Train DeepLabCut Model¶
This tool uses 2.0 compute credits per hour.
DeepLabCut is an open-source library for pose estimation based on deep learning. This tool allows users to train a DeepLabCut model. The output model can be used downstream to perform pose estimation on behavioral movies.
DeepLabCut Version Compatibility
This tool uses DeepLabCut version 3.0.0.rc7
Parameters¶
| Parameter | Required? | Default | Description |
|---|---|---|---|
| Labeled Data Zip File | True | N/A | A zip file containing the labeled data to use for training. |
| Config File | True | N/A | A config file describing the configuration of the DLC project. Includes the body parts and skeleton of the animal pose, training fraction, network and augmenter types, etc. |
| Engine | False | pytorch | Specifies the backend engine to use for training the network. Either "tensorflow" or "pytorch". If empty, reads the engine value in the input config.yaml. DeepLabCut recommends using pytorch since it is faster. The tensorflow backend will be deprecated by the end of 2024. |
| Training Fraction | False | 0.95 | The fraction of labeled data to use for training the network, the remainder is used for testing the network for validation. This value is automatically calculated if “Train Video Files” and “Test Video Files” are specified. If empty, and no “Train Video Files” and “Test Video Files” are specified, then the value in the input config file is used. |
| P Cutoff | False | 0.6 | Cutoff threshold for the confidence of model results. If used, then results with a confidence below the cutoff are omitted from analysis. This is used when generating evaluation results, and can be used downstream to filter analyses on novel videos. |
| Train Files | True | auto | Comma-separated list of video file names from labeled data to use for training the network. Must be specified if “Test Video Files” is passed. If empty, then train images are automatically selected from labeled data. |
| Test Files | True | auto | Comma-separated list of video file names from labeled data to use for testing the network. Must be specified if “Train Video Files” is passed. If empty, then test images are automatically selected from labeled data. |
| Net Type | True | resnet_50 | Type of network. Currently supported options are: resnet_50, resnet_101, resnet_152, mobilenet_v2_1.0, mobilenet_v2_0.75, mobilenet_v2_0.5, mobilenet_v2_0.35, efficientnet-b0, efficientnet-b, efficientnet-b2, efficientnet-b3, efficientnet-b4, efficientnet-b5, efficientnet-b6 |
| Augmenter Type | True | default | Type of augmenter. Currently supported options are: default, scalecrop, imgaug, tensorpack, deterministic |
| Train Pose Config File | False | N/A | A config file describing the configuration settings for training the network. |
| Number of Snapshots To Evaluate | True | all | Sets how many snapshots are evaluated, i.e. states of the trained network. Every saving iteration a snapshot is stored, however only the last “Number of Snapshots to Evaluate” are kept. If "all", then all snapshots are evaluated. |
| Save Iterations | True | 50000 | The interval to save an iteration as a snapshot. If empty, then the value in pose_config.yaml is used. |
| Max Iterations | True | 250000 | The maximum number of iterations to train the model. If empty, then the value in pose_config.yaml is used. |
| Allow Growth | True | True | For some smaller GPUs, memory issues happen. If true then, the memory allocator does not pre-allocate the entire specified GPU memory region, instead starting small and growing as needed. See issue: https://forum.image.sc/t/how-to-stop-running-out-of-vram/30551/2 |
| Keep Deconvolution Weights | True | True | Restores the weights of the deconvolution layers (and the backbone) when training from a snapshot. Note that if you change the number of bodyparts, you need to set this to false for re-training. |
| Pytorch Config File | False | N/A | A config file describing the pytorch configuration settings for training the network. |
| Device | False | auto | (pytorch only) The torch device to train on (such as "cpu", "cuda", "mps", "auto"). Overrides the value set in pytorch_config.yaml. |
| Batch Size | False | 2 | (pytorch only) The batch size to train with. Overrides the value set in pytorch_config.yaml. Small batch sizes (i.e., value of one) is good for training on a CPU, but this tool runs on a GPU instance. For GPUs a larger batch size should be used. The value should be the biggest power of 2 where you don't geta CUDA out-of-memory error, such as 8, 16, 32 or 64. This also allows you to increase the learning rate (empirically you can scale the learning rate by sqrt(batch_size) times). By default a batch size of 2 is used as this has shown to stay within memory limits on the instance used for this tool. |
| Epochs | False | 200 | (pytorch only) The maximum number of epochs to train the model. Overrides the value set in pytorch_config.yaml. |
| Save Epochs | False | 50 | (pytorch only) The number of epochs between each snapshot save. Overrides the value set in pytorch_config.yaml. |
| Detector Batch Size | False | N/A | (pytorch only) Only for top-down models. The batch size with which to train the detector. Overrides the value set in pytorch_config.yaml. |
| Detector Epochs | False | N/A | (pytorch only) Only for top-down models. The maximum number of epochs to train the model. Overrides the value set in pytorch_config.yaml. Setting to 0 means the detector will not be trained. |
| Detector Save Epochs | False | N/A | (pytorch only) Only for top-down models. The number of epochs between each snapshot of the detector is saved. Overrides the value set in pytorch_config.yaml. |
| Pose Threshold | False | 0.1 | (pytorch only) Used for memory-replay. pseudo predictions that are below this are discarded for memory-replay. |
| Test Pose Config File | False | N/A | A config file describing the configuration settings for testing (evaluating) the network. |
| Plot Evaluation Results | True | False | Plots the predictions of evaluation results on the train and test images. |
| Body Parts To Evaluate | True | all | The average error for evaluation results will be computed for those body parts only. The provided list has to be a subset of the defined body parts. Otherwise, set to “all” to compute error over all body parts. |
| Rescale | True | False | Evaluate the model at the 'global_scale' variable (as set in the pose_config.yaml file for a particular project). I.e. every image will be resized according to that scale and prediction will be compared to the resized ground truth. The error will be reported in pixels at rescaled to the original size. I.e. For a [200,200] pixel image evaluated at global_scale=.5, the predictions are calculated on [100,100] pixel images, compared to 1/2*ground truth and this error is then multiplied by 2. The evaluation images are also shown for the original size. |
| Per Keypoint Evaluation | True | False | Compute the train and test RMSE for each keypoint, and save the results to a {model_name}-keypoint-results.csv in the evalution-results folder |
| Generate Maps | True | False | Plot the scoremaps, locref layers, and PAFs from the evaluation results. |
| Optimal Snapshot Metric | True | Test Error | The type of error from the evaluation results to minimize in order to find the optimal snapshot. Options are: Train Error, Test Error, Train Error w/ p-cutoff, Test Error w/ p-cutoff |
| Save Optiomal Snapshot | True | True | Only keep the snapshot with the smallest error from the evaluation results in the zipped model output. The error to minimize is indicated by the “Optimal Snapshot Error Metric” parameter. This significantly reduces the size of the zipped model output uploaded to IDEAS. If set to false, then all snapshots evaluated are included in the zipped model output. This is controlled by the “Snapshots to Evaluate” parameter. |
Inputs¶
| Source Parameter | File Type | File Format |
|---|---|---|
| Labeled Data Zip File | dlc_labeled_data, dlc_labeled_data | zip, tar.gz |
| Config File | dlc_config | yaml |
| Train Pose Config File | dlc_config | yaml |
| Pytorch Config File | dlc_config | yaml |
| Test Pose Config File | dlc_config | yaml |
The following sections explain in further detail the expected format for these input files.
Labeled Data Zip File¶
This input is a .zip file containing the labeled data from DLC that should be used for training the model.
The contents of this folder should correspond with the labeled-data folder inside a DLC project.
When a new DLC project is created, the labeled-data folder is automatically created.
The contents of this folder should look something like the following:
<video 1>CollectedData_<user>.csvCollectedData_<user>.h5image00xxxx.png- ...
<video 2>- ...
<video n>
The labeled data consists of a folder for every video selected for training/testing.
Within each folder, there should be many .png files containing the frame extracted from the corresponding video.
There should also be a csv and h5 file containing the manually labeled pose estimates for each image in the folder.
These images need to be labeled using the DLC GUI, prior to training the model in IDEAS.
To label images using DLC, the library must first be installed, following these instructions.
Launch DLC and create a new project, select the videos that should be used for training & testing the network. Once the project is created, the config file should be edited to specify the body parts and skeleton of the animal pose, as well as any additional advanced configurations that should be applied to the model.
Next, frames must be extracted from the selected videos using the Extract Frames panel in the GUI.
Once frames are extracted, each frame can be labeled using the Label Frames panel in the GUI.
After all frames in all videos have been labeled, navigate to the project folder in a file explorer, and compress the labeled-data folder as a zip file.
This file can be uploaded to IDEAS and set to the DLC Labeled Data type
Config File¶
Every DLC project has a config.yaml located at the top-level of the project folder.
This configures the DLC project.
The most important configuration in this file is the body parts and skeleton of the pose which should be used for training.
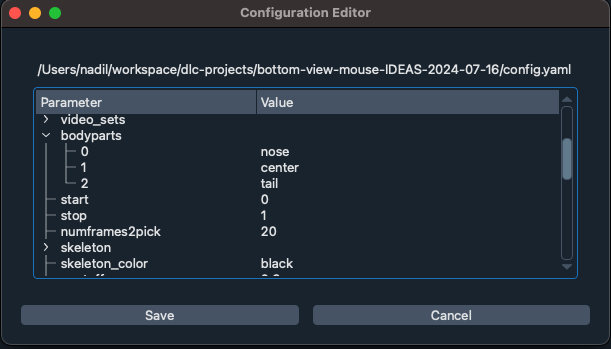
There are many other important parameters that can be changed from default values for advanced use cases. These parameters include the training fraction, the engine to use for training, the p-cutoff value to use for evaluation. These three values can also be specified in the parameters of this tool due to their importance in model training and evaluation. There are additional properties in the config which can be adjusted as well, read more here.
Train Pose Config File¶
The train pose config file configures the training settings for a model. It is automatically generated by DLC, but it can be edited for advanced use cases. Some parameters that can be adjusted includes the learning rate to use for iteration/epoch ranges, the max number of epochs/iterations, the frequency to save snapshots, the max snapshots to take, etc. If this file is not provided, the default file generated by DLC will be used. In order to generate this file locally using DLC, you will need to create training dataset to auto generate this file.
Pytorch Config File¶
The pytorch config file configures the pytorch training settings for a model. It is automatically generated by DLC, but it can be edited for advanced use cases. Some parameters that can be adjusted includes the maximum number of epochs, batch size, top-level detectors, etc. If this file is not provided, the default file generated by DLC will be used. In order to generate this file locally using DLC, you will need to create training dataset to auto generate this file.
Test Pose Config File¶
The test pose config file configures the settings for evaluating a model. It is automatically generated by DLC, but it can be edited for advanced use cases. If this file is not provided, the default file generated by DLC will be used. In order to generate this file locally using DLC, you will need to create training dataset to auto generate this file.
Description¶
The tool goes through the following steps to train and evaluate a dlc network using input labeled data.
Create New Project¶
First a new project is created.
This executes the function deeplabcut.create_new_project.
The input labeled data and config file are copied to the new project.
Any config values passed in the parameters, i.e., Engine, Training Fraction, and P Cutoff, are then updated in config file of the new project.
Create Training Dataset¶
Using the new project, a training dataset is created from the labeled data. This executes the function deeplabcut.create_training_dataset.
By default, DLC will use the user-specified Training Fraction to automatically, randomly split the labeled data into train and test data.
However, it's also possible to specify a custom split of train and test data by specifying the videos names (excluding the file extension) to use for training as a comma-separated list in the Train Files parameter, and the video names to use for testing as a comma-separated list in the Test Files parameter.
The videos in Train Files and Test Files are not allowed to overlap.
The Net Type and Augmenter Type are also used to populate the pose_cfg.yaml file created for the new network. This config file controls many settings for training, which can be tweaked for advanced use cases. A pose_cfg.yaml can also be provided as input in the Train Pose Config parameter and used for training the network.
See here for more info about this file.
Train Network¶
The next step is training the model.
This executes the function deeplabcut.train_network.
If Train Pose Config, Test Pose Config, or Pytorch Config files are provided as input, then the files are copied to the dlc-models or dlc-models-pytorch folder before starting training.
By default, all snapshots are saved during model training so that there is enough data to accurately assess the training performance over epochs/iterations.
Evaluate Network¶
The final step is evaluating the network.
This executes the function deeplabcut.evaluate_network.
By default, this evaluates all snapshots that were saved from training.
From the evaluation results, an optimal snapshot is computed using the Optimal Snapshot Metric parameter.
By default, only the optimal snapshot is saved in the output zipped model in order to reduce the size of the model uploaded to IDEAS.
This can be turned off using the Save Optiomal Snapshot parameter
Outputs¶
Trained Model¶
Once training completes the dlc-models or dlc-models-pytorch folder is compressed into an output zip file.
This zip file will be compatible with the DeepLabCut Pose Estimation tool, and can be used to analyze new videos.
If Save Optiomal Snapshot is true, then only the optimal snapshot is saved in the output zip file in order to reduce the size of the model uploaded to IDEAS.
A few summary evaluation results are also copied to the models folder prior to compression, including the CombinedEvaluation-results.csv, and two .h5 files containing the error distribution of the optimal snapshot, with and without a p-cutoff.
Previews¶
This output has several previews to help visualize the training & evaluation results of the model.
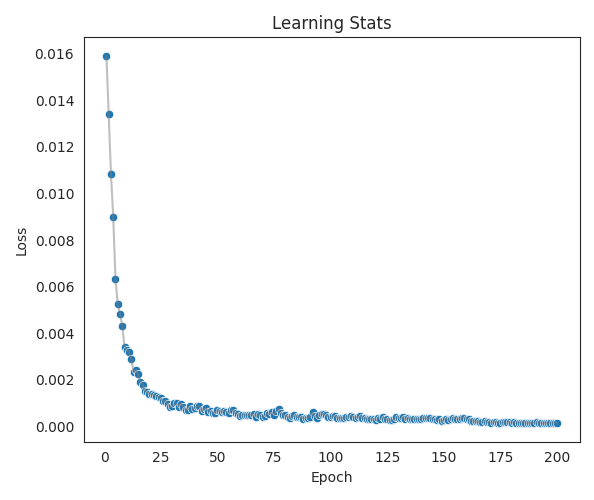
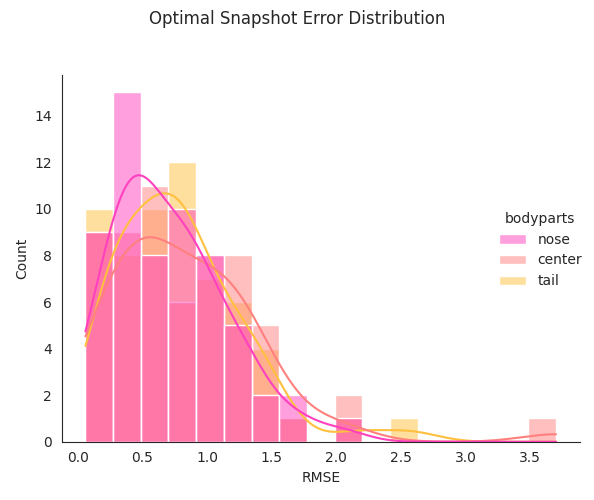
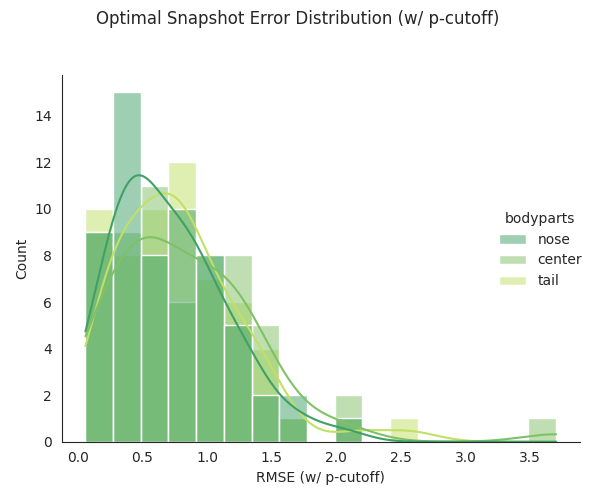
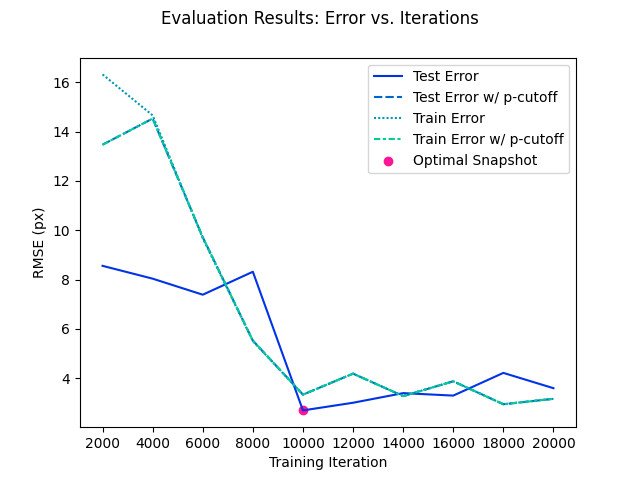


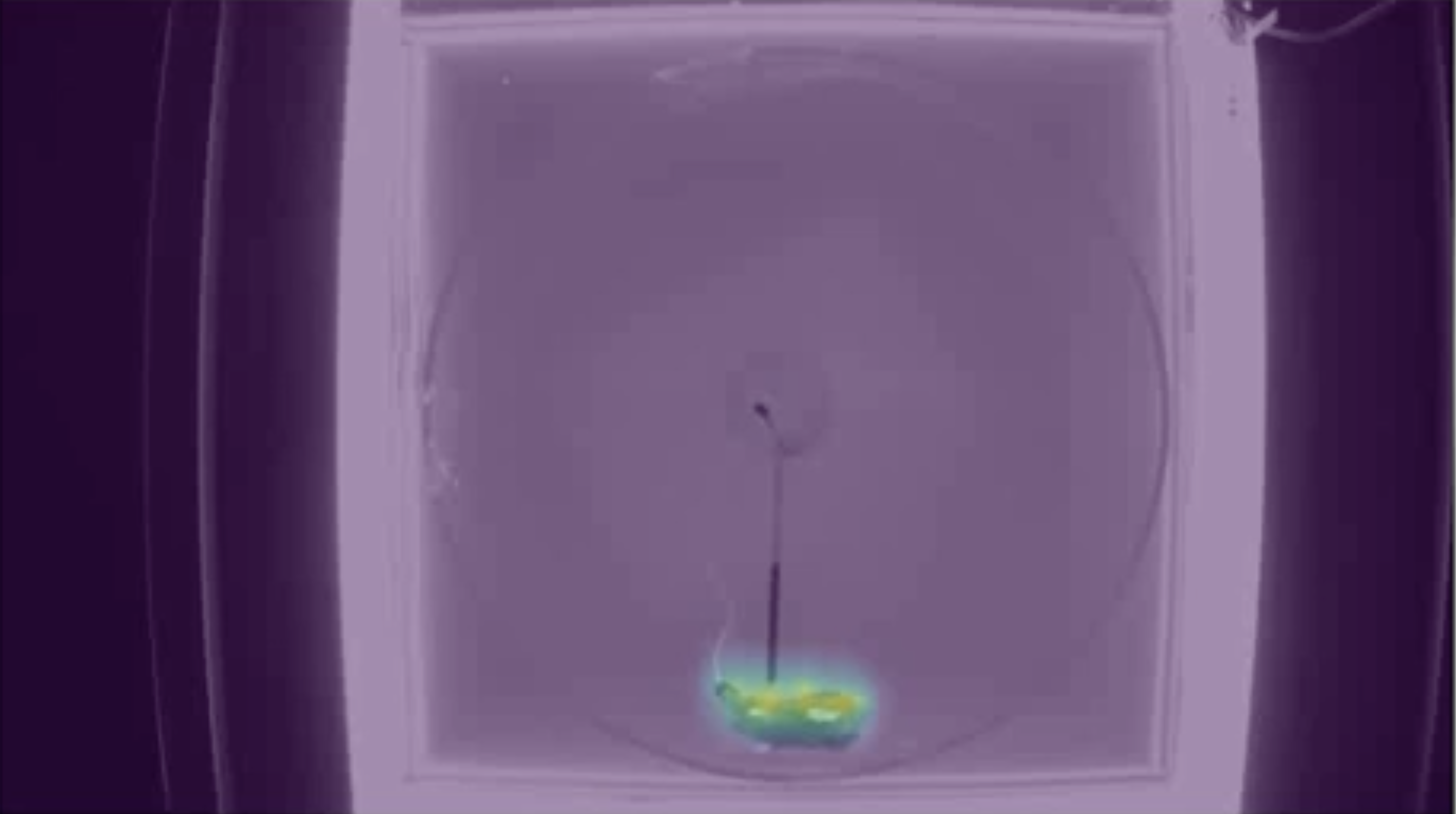
Evaluation Results¶
In addition to the output trained model, the evaluation-results or evaluation-result-pytorch is compressed into an output zip file.
This is a separate output file since evaluation results can become significantly large in size if Plot Evaluation Results or Generate Maps is set to true.
This output shares the same previews as the trained model output.
Next Steps¶
After training a model, it can be applied on new videos using the DeepLabCut Pose Estimation tool.
FAQ¶
- Which engine should I use?
- DeepLabCut recommends using pytorch since it is faster. The tensorflow backend will be deprecated by the end of 2024.
- Why is my task getting cancelled after hours of running?
- There is a 6 hour timeout on tasks in IDEAS. If you suspect the task is timing out, try decreasing
Epochsparameter if you are using thepytorchengine, or decrease theMax Iterationsparameter if you are usingtensorflowengine.
- There is a 6 hour timeout on tasks in IDEAS. If you suspect the task is timing out, try decreasing
- Can you create multiple shuffles using this tool?
- This tool is configured to only train a single network, therefore only one shuffle is required for this tool and cannot be changed using a parameter.
- To train multiple networks simply execute multiple rows of this tool in an analysis table for batch execution.
- Each output trained model can be compared for performance after all task complete.